Welcome to iFISH4U
This website provides information and support for running the iFISHkit pipeline for designing oligonucleotide (oligo) based probes for DNA and RNA fluorescence in situ hybridization (FISH) developed in the Bienko-Crosetto Lab.
iFISHkit is an updated version of the ifpd probe design pipeline that was used to create the iFISH repository of probes described in our 2019 iFISH paper.
iFISHkit is developed mostly in Python and in C, and is available as a Docker or Singularity image. To directly proceed with installation and start designing your iFISH probes, follow the instructions on our Github repository.
Below, we provide information on iFISH probe design and how to successfully run iFISHkit. Additionally, we provide the latest version of our T7-Driven Amplification (TDA) protocol.
To know more about iFISH, please also watch this webinar.
We define an iFISH probe as a set of non-overlapping, single-stranded DNA oligos that can be used—as a pool—to visualize a single target of interest (DNA locus or RNA transcript).
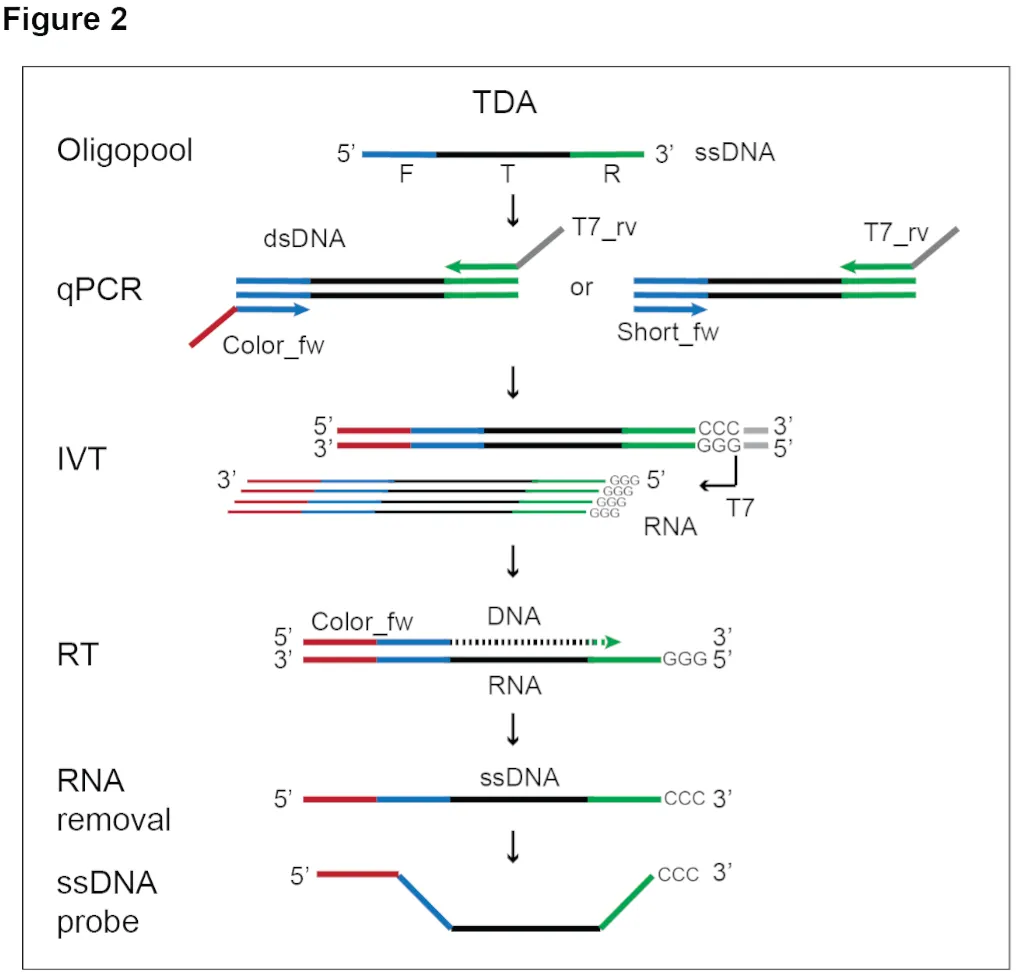
Each oligo within an iFISH probe consists of a central sequence complementary to the target (T) sequence (typically, 40 nucleotide (nt) for DNA and 30 nt for RNA), flanked on both sides by one or more 20 nt extensions (Figure 1): i) a forward (F) and a reverse (R) sequence on the 5’ and 3’ side, respectively, which serve as priming sequences for PCR during probe production; and ii) one color (C) sequence introduced during the PCR step in the TDA protocol. The C sequence serves as docking site for a secondary oligo coupled with one or more fluorophores, for probe detection.
Depending on the target type (DNA or RNA) and size, and on the sample type, a single iFISH probe may comprise between few dozen (min 10 oligos for RNA FISH) up to several thousand oligos (for DNA FISH in challenging samples, such as formalin-fixed paraffin-embedded, FFPE samples) (Figure 1). While a single oligo in an iFISH probe can only yield a weak fluorescence signal that cannot be distinguished from background in typical cell and tissue preparations, the accumulation of multiple oligos on the target region produces a brighter fluorescent spot/dot that can be detected with conventional widefield microscopes.
iFISHkit can be run for any organism for which a reference genome or transcriptome sequence is available and requires either genomic coordinates or a DNA/RNA sequence as input.
For each given genomic region or transcript of interest, iFISHkit performs the following actions, in order:
- Extract all k-mers of the desired length (typically, 40 nt for DNA and 30 nt for RNA).
- Measure off-target k-mer homology across the genome or transcriptome using nHUSH, a rapid aligner that we have developed, which is specifically designed for finding off-targets.
- Analyze all k-mers for melting temperature and possible secondary structures.
- Create a database of all k-mers in the target region, reporting off-target homology, GC-content, melting temperature, homopolymer stretches and secondary structures.
- Attribute a penalty to each k-mer, by compiling all of the parameters above into a single value for each k-mer (with a lower cost indicating a ‘better’ k-mer for specific binding to the target region).
- Pre-filter the k-mer database by comparing the sequence of each k-mer to a blacklist of recurrent sequences in the reference genome or transcriptome (i.e., sequences occurring more than 100 times).
-
Recursively construct probes as follows:
- Construct probe candidates using our custom script escafish to minimize the penalty of individual k-mers and the distance between consecutive k-mers, for a desired number of oligos in the probe.
- Select the best probe candidate.
- Test the exact off-target homology of each k-mer in the selected probe candidate using HUSH (an older and slower, yet more thorough version of nHUSH).
- If unacceptable k-mers were included in the probe candidate, filter these out from the k-mer database and repeat probe construction.
- If no probe can be constructed with the desired number of k-mers, repeat the process but querying for fewer k-mers
- Extend each oligo sequence in the probe with a probe-specific pair of F and R sequences (see Figure 1).
- Return the final probe (or no probe if insufficient suitable k-mers were found in the region of interest).
Once probe design is complete, we purchase the designed oligos synthesized as oligopools. Depending on the total number of probes, and the number of oligos per probe, multiple probes can be synthesized together as a single oligopool, provided that each probe has a distinct F-R sequence pair.
Oligopools of different size (i.e., number of distinct oligo sequences per pool) can be purchased from companies such as Twist Bioscience or GenScript. The oligopools are then used as input for the TDA protocol described below.
A single probe usually targets a single site, e.g., a gene locus or a transcript of interest. Ideally, a single probe should produce a single fluorescence spot/dot for each locus/transcript targeted. For example, in diploid cells, a DNA iFISH probe targeting a single locus should yield 2–4 fluorescence dots per nucleus, depending on the cell cycle stage of the cells.
The brightness of each FISH dot is directly influenced by the number of oligos contained in the probe, with a larger number of oligos thus being advised when higher detection sensitivity is required. For DNA iFISH on cultured cells, we recommend at least 100 oligos per probe. For iFISH on fresh frozen or FFPE samples, we instead advise a minimum of 1,000 and 3,000 oligos per probe, respectively.
For RNA iFISH, probe design options are influenced by transcript length. We recommend a minimum of 30–50 oligos per target consensus coding sequence (CCDS), but higher numbers will give better results. However, excessive oligo numbers can result in larger fluorescent dots that can be difficult to separate, especially when targeting very long transcripts. For this reason, we recommend designing RNA iFISH probes to contain at most 150–200 oligos per CCDS.
An important aspect to consider, especially when designing DNA iFISH probes, is the distribution of the oligos along the targeted linear genome sequence. Ideally, the oligos should be evenly spaced, without forming clusters, as this may result in detection of two (or more) smaller fluorescence dots instead of a single, larger dot. The length of the region targeted also influences the final signal: for example, larger DNA regions, which may form separate globules in 3D (e.g., topologically associating domains, TADs), may result in 'splitting' of the fluorescence signal and yield more than one single fluorescence dot per probe.
iFISHkit aims at designing a probe that is compact (i.e., with small gaps between consecutive oligos) but contains as many high-quality oligos as possible. In the iFISHkit output, the pair-weight parameter (pw) illustrates this balance, with low values (below 1e-6) indicating that the pipeline found a sufficient number of high-quality oligos, while high values (above 1e-3) indicate that the probe had to be spread out to find enough acceptable oligos. As we typically image DNA iFISH probes on a widefield microscope with 100x magnification and 65 nm pixel size, for this setup we recommend avoiding gaps larger than 2 kilobases between consecutive oligos in the same probe. However, the maximum gap size needs to be adjusted depending on the imaging modality and microscope setup available.
For dedicated applications, multi-probe panels can be designed to visualize large DNA regions or long transcripts (e.g., pre-mRNA containing large intronic sequences) without covering the entire sequence with oligos. For instance, spotting probes are a collection of DNA iFISH probes targeting multiple evenly spaced loci along the same chromosome or chromosome arm, which enable the visualization of chromosomal territories as 'clouds' of separate fluorescence dots. Probes in a spotting probe can be labeled in the same color or, alternatively, different colors can be used. For example, alternating colors can be used to label probes targeting different chromatin compartments (e.g., A and B compartments identified by high-throughput chromosome conformation capture techniques).
The iFISHkit pipeline can currently only be used to design single probes; however, spotting probes or other custom multi-probe panels can easily be designed by providing the coordinates of each probe as input. If you want to have the probes in a multi-probe panel carry different C(olour) sequences, make sure to use distinct pairs of F and R sequences if the probes are to be synthesized together (see next section).
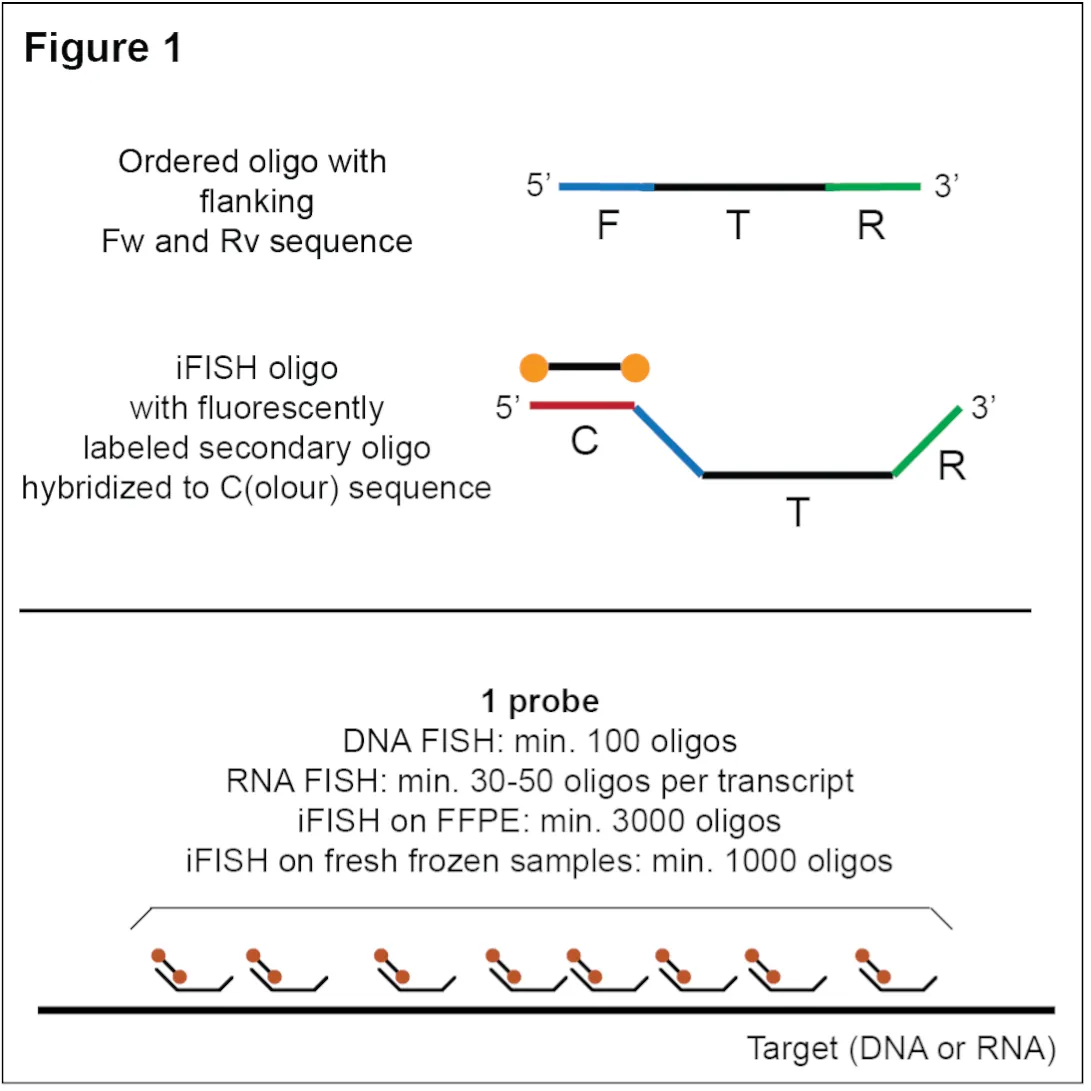
To generate iFISH probes from synthetic oligopools using the primers described below, we follow an updated version of the TDA protocol described in our 2019 iFISH paper.
In addition to an oligopool, the following primers must be separately purchased for each probe before starting the TDA protocol:
- Color_fw primer, matching the F sequence of each oligo in the probe and containing a 5’ extension that will incorporate the C(olor) sequence for probe readout on the 5’ end of the dsDNA during the PCR step in the TDA protocol (Figure 2).
- T7_rv primer, binding the R sequence of each oligo in the probe and containing a 5’ extension that will incorporate the T7 promoter sequence on the 3’ end of the dsDNA during the PCR step.
Alternatively, the probes may be first pre-amplified from the oligopool to produce a PCR product 'stock', which can be frozen and later used as input to the IVT reaction in the TDA protocol. In this case, the following primers need to be purchased for each probe:
- Short_fw primer, matching the F sequence of each oligo in the probe (Figure 2).
- T7_rv primer, binding the R sequence of each oligo in the probe and containing a 5’ extension that will incorporate the T7 promoter sequence on the 3’ end of the dsDNA during the PCR step.
- Color_fwd primer, which is in this case used to incorporate the C sequence for probe readout during the reverse transcription (RT) step in the TDA protocol (Figure 2).
In Table 1 we provide a list of Color_fw, Short_fw, and T7_rv primers, as well as the sequence of fluorescently labeled detection oligos that we commonly use.